
I am a researcher at the ERNIE Team, Baidu, supervised by Prof. Rui Liu, focusing on audio-visual understanding and speech generation. I have published at top-tier conferences such as AAAI and ICASSP, and contributed to ERNIE 5.0. Google Scholar
I am always open to research collaborations and new opportunities. If you are interested in working together or have any exciting prospects, feel free to reach out at shuwei_he@163.com.
🔥 News
- 2026.02: 🚀 Open-sourced Eureka-Audio, a lightweight large audio understanding model. With only 1.7B parameters, it outperforms several significantly larger models. The preprint is now available on arXiv.
- 2026.01: ⭐ Participated in the core development of Baidu’s ERNIE 5.0
 and was listed as a contributor in the official technical report.
and was listed as a contributor in the official technical report. - 2025.08: 🎊 Received an official offer from the Baidu ERNIE Team .
- 2025.02: 💼 Joined the Baidu ERNIE Foundation Model Team as a Large Model Algorithm Intern.
- 2024.12: 🎉 Our paper MS$^2$KU-VTTS was accepted by ICASSP 2025.
- 2024.12: 🎉 Our paper M$^2$SE-VTTS was accepted by AAAI 2025.
📝 Publications
Representative Work
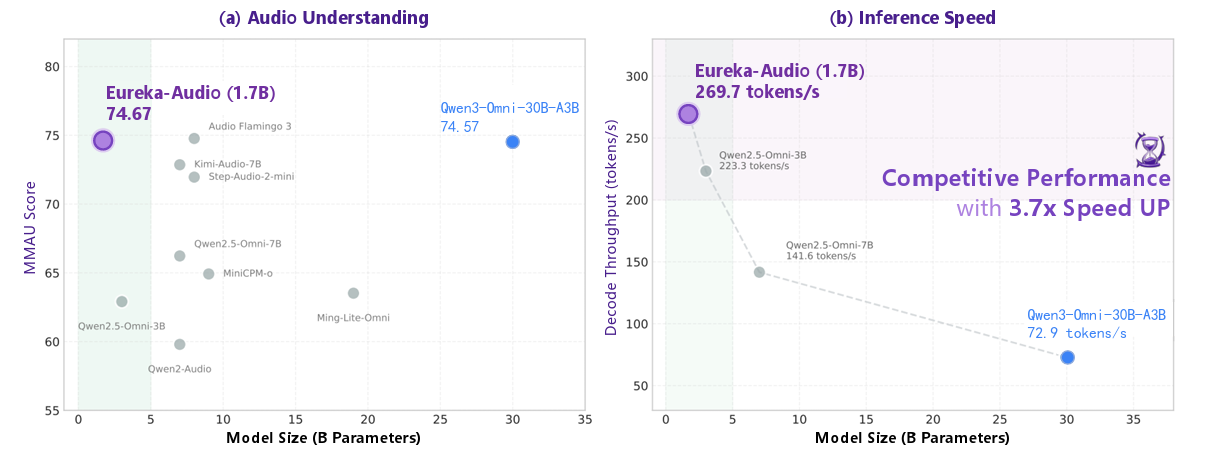
Eureka-Audio: Triggering Audio Intelligence in Compact Language Models
Dan Zhang*, Yishu Lei*, Jing Hu*, Shuwei He*, Songhe Deng, Xianlong Luo, Danxiang Zhu, Shikun Feng, Rui Liu, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang (* Equal Contribution / * 共同一作)
- This paper introduces Eureka-Audio, a compact 1.7-billion-parameter audio language model that utilizes a sparsely activated Mixture-of-Experts adapter and a novel data synthesis pipeline called DataFlux to achieve competitive audio understanding and significantly faster inference speeds compared to much larger baseline models.
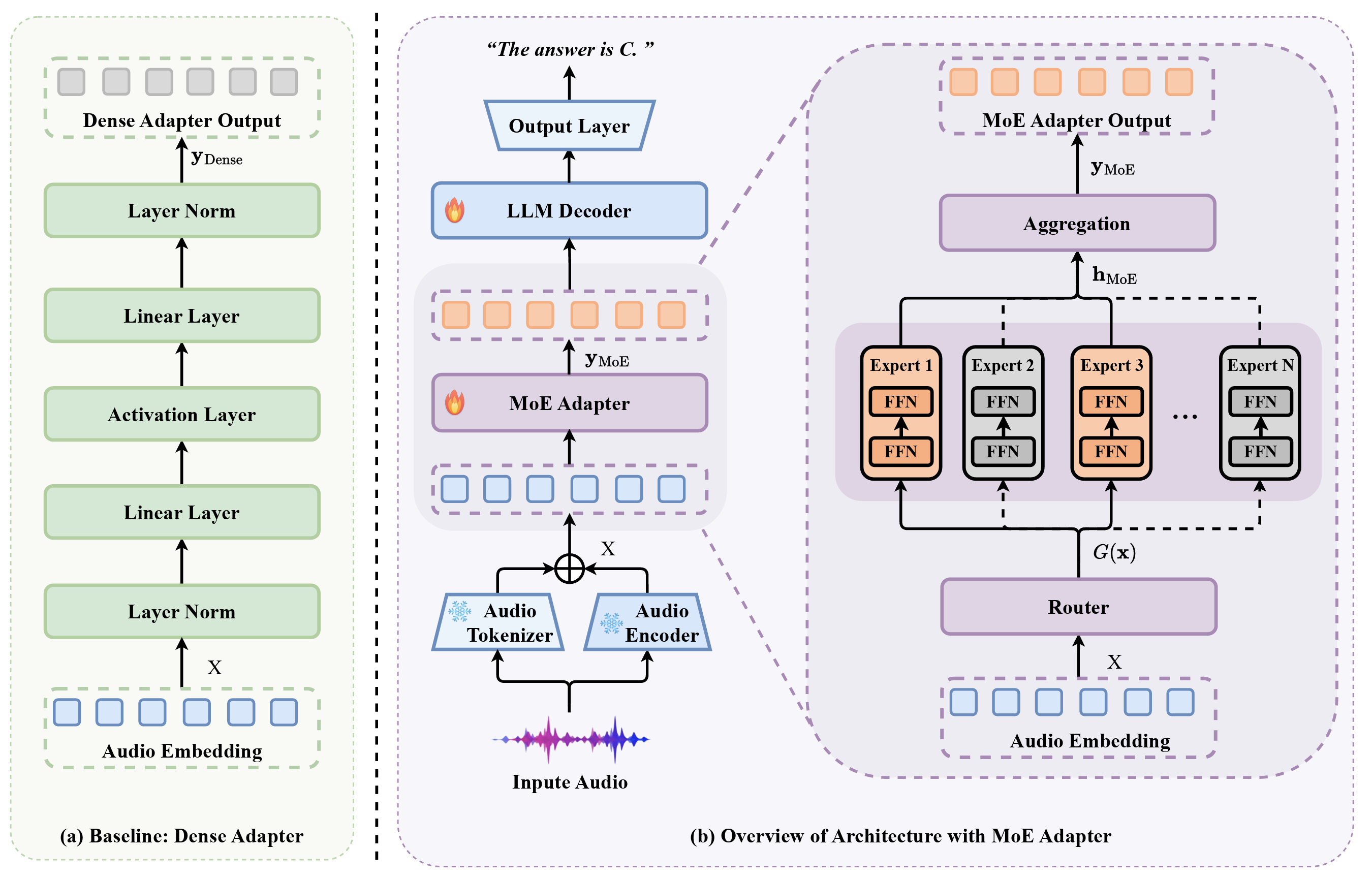
MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free
Yishu Lei*, Shuwei He*, Jing Hu, Dan Zhang, Xianlong Luo, Danxiang Zhu, Shikun Feng, Rui Liu, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang (* Equal Contribution / * 共同一作)
- This paper introduces the MoE-Adapter, a sparse Mixture-of-Experts architecture designed to mitigate gradient conflicts in Large Audio Language Models by dynamically routing heterogeneous acoustic inputs to specialized experts, effectively disentangling speech, music, and sound for superior cross-modal alignment.
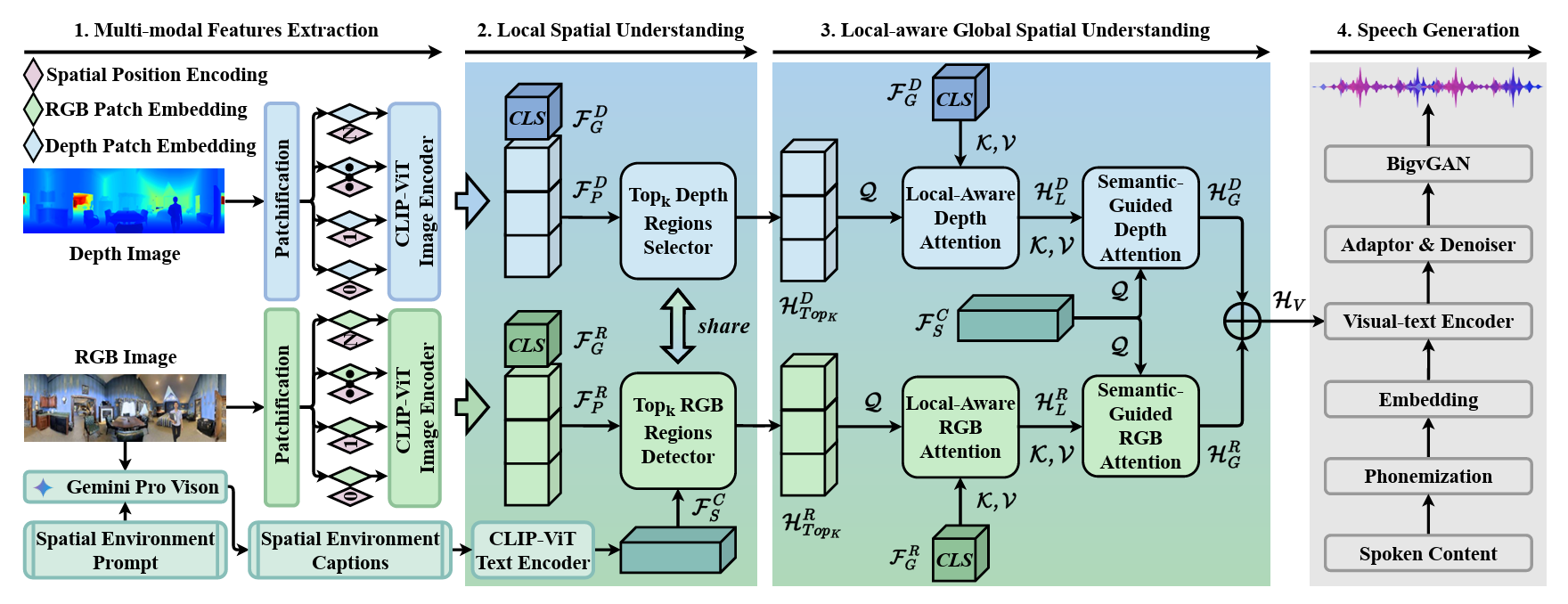
Multi-modal and Multi-scale Spatial Environment Understanding for Immersive Visual Text-to-Speech
Rui Liu†, Shuwei He, Yifan Hu, Haizhou Li († Corresponding Author / 通讯作者, Shuwei He is the first student author / 何树伟为导师外学生一作)
- This paper introduces M$^2$SE-VTTS, an innovative multi-modal and multi-scale framework that integrates RGB and depth images with environment captions to effectively model local and global spatial contexts for synthesizing immersive reverberant speech.
More Publications
- arXiv 2026 ERNIE 5.0 Technical Report, ERNIE Team, Baidu (Shuwei He as Core Contributor / 何树伟为核心参与者)
- arXiv 2025 CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation, Jing Hu, Danxiang Zhu, Xianlong Luo, Dan Zhang, Shuwei He, Yishu Lei, Haitao Zheng, Shikun Feng, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang
- ICASSP 2025 Multi-Source Spatial Knowledge Understanding for Immersive Visual Text-to-Speech, Shuwei He (First Author / 第一作者), Rui Liu
🎖 Honors and Awards
- 2025.12 National Scholarship
- 2021.12 National Scholarship
📖 Educations
- 2023.08 - 2026.06, Master, Inner Mongolia University, Artificial Intelligence
💻 Internships
- 2025.02 - 2026.01, Algorithm Intern, Baidu ERNIE Bot, China.