
I am currently a Researcher at the ERNIE Team, Baidu, where I contribute to the overall development of Omni foundation models. If you are interested in academic collaboration, please feel free to contact me at shuwei_he@163.com.
I received my master’s degree from Inner Mongolia University (内蒙古大学), under the supervision of Prof. Rui Liu. In both academic research and project development, I have worked closely with Dr. Haifeng Wang from Baidu and Prof. Haizhou Li from The Chinese University of Hong Kong, Shenzhen.
My research has been published in leading international conferences in artificial intelligence and speech processing, including ACL, AAAI, and ICASSP. I have also actively contributed to the development of the ERNIE 5.0 foundation model. Google Scholar
🔥 News
- 2026.04: 🎉 Two papers (MoE Adapter and CORD) were accepted by Findings of ACL 2026.
- 2026.02: 🚀 Open-sourced Eureka-Audio, a lightweight large audio understanding model. With only 1.7B parameters, it outperforms several significantly larger models. The preprint is now available on arXiv.
- 2026.01: ⭐ Participated in the core development of Baidu’s ERNIE 5.0 (文心一言)
 and was listed as a contributor in the official technical report.
and was listed as a contributor in the official technical report. - 2025.12: 🎊 Awarded the National Scholarship (研究生国家奖学金) during my master’s studies.
- 2025.12: 🎊 Academic Scholarship during my master’s studies (研究生学业奖学金).
- 2025.08: 💼 Received an official offer from the Baidu ERNIE Team (文心一言) .
- 2025.02: 💼 Joined the Baidu ERNIE Foundation Model Team (文心一言) as a Large Model Algorithm Intern.
- 2024.12: 🎉 Our paper MS$^2$KU-VTTS was accepted by ICASSP 2025.
- 2024.12: 🎉 Our paper M$^2$SE-VTTS was accepted by AAAI 2025.
- 2023.12: 🎊 Academic Scholarship during my master’s studies (研究生学业奖学金).
📝 Publications
Representative Work
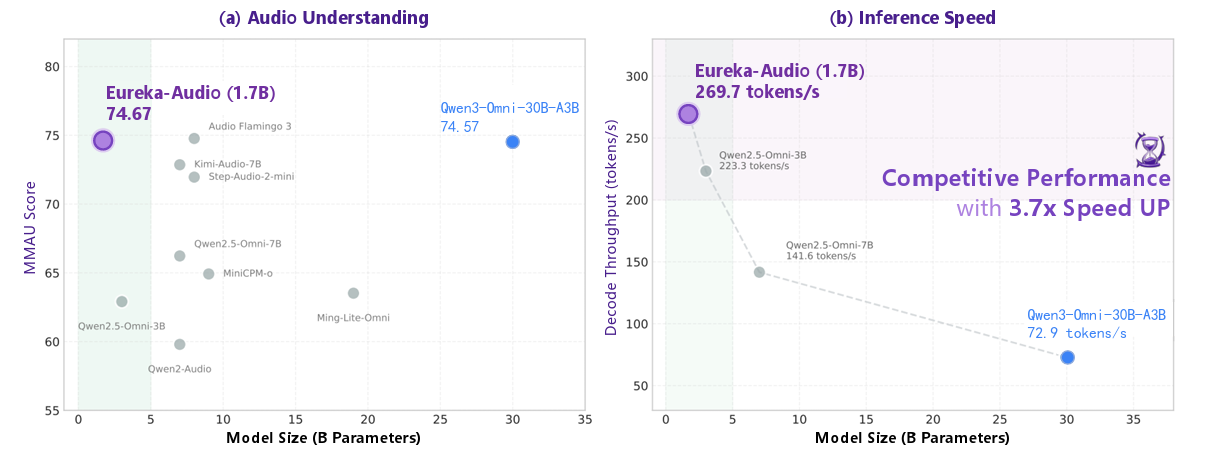
Eureka-Audio: Triggering Audio Intelligence in Compact Language Models
Dan Zhang*, Yishu Lei*, Jing Hu*, Shuwei He*, Songhe Deng, Xianlong Luo, Danxiang Zhu, Shikun Feng, Rui Liu, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang (* Equal Contribution / * 共同一作)
- This paper introduces Eureka-Audio, a compact 1.7-billion-parameter audio language model that utilizes a sparsely activated Mixture-of-Experts adapter and a novel data synthesis pipeline called DataFlux to achieve competitive audio understanding and significantly faster inference speeds compared to much larger baseline models.
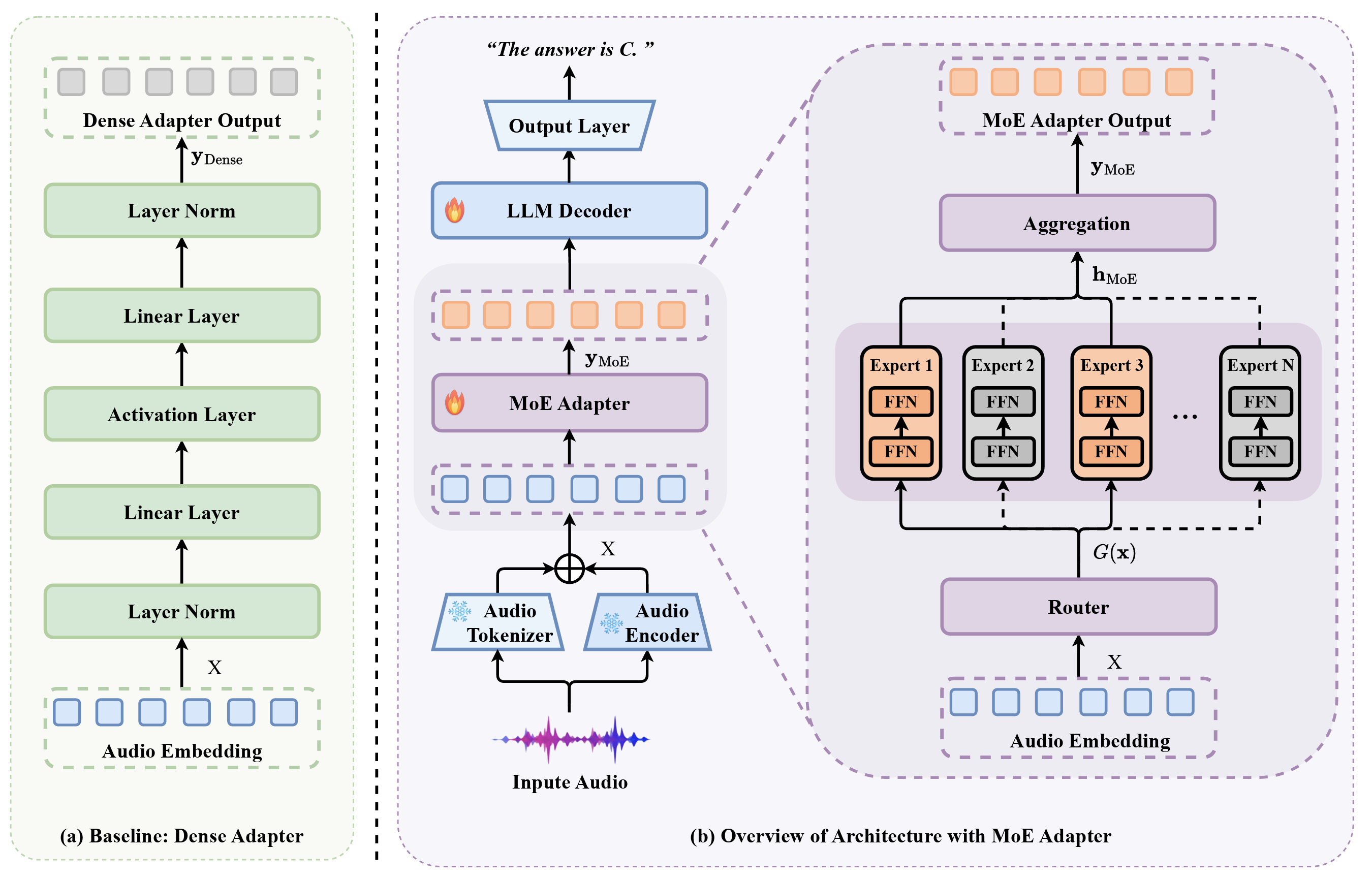
MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free
Yishu Lei*, Shuwei He*, Jing Hu, Dan Zhang, Xianlong Luo, Danxiang Zhu, Shikun Feng, Rui Liu, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang (* Equal Contribution / * 共同一作)
- This paper introduces the MoE-Adapter, a sparse Mixture-of-Experts architecture designed to mitigate gradient conflicts in Large Audio Language Models by dynamically routing heterogeneous acoustic inputs to specialized experts, effectively disentangling speech, music, and sound for superior cross-modal alignment.
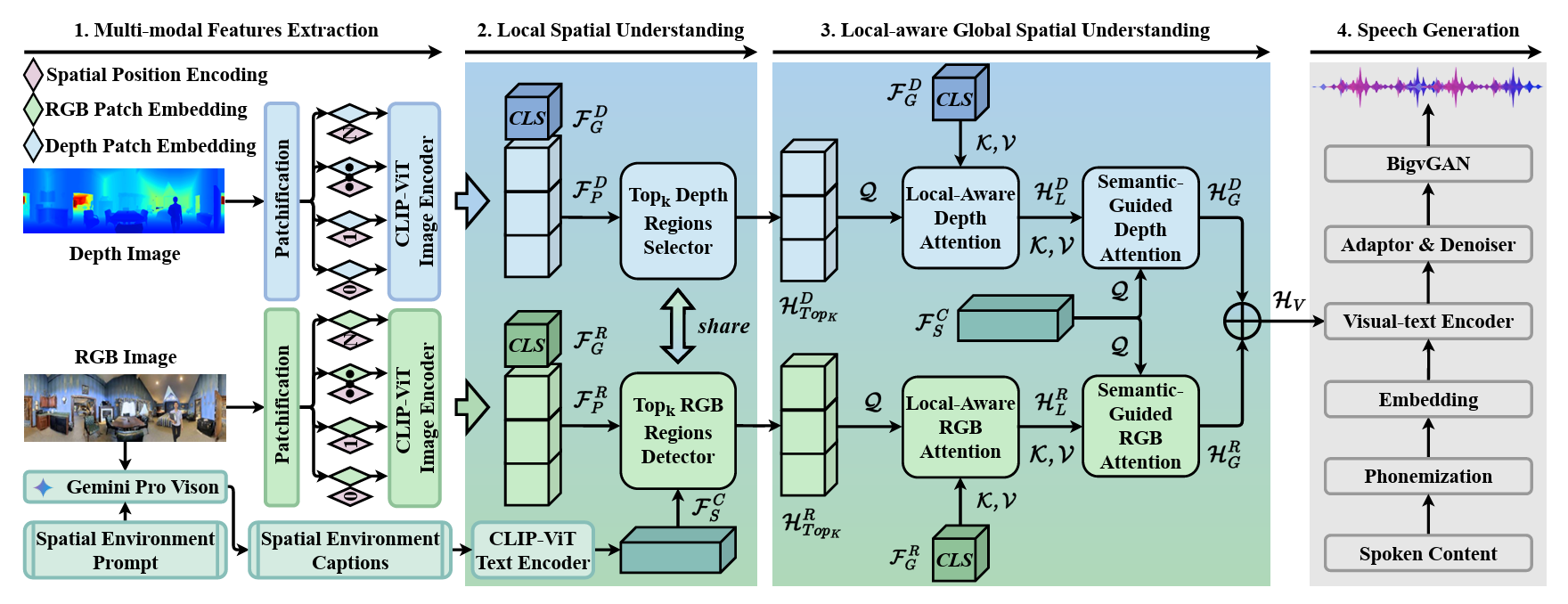
Multi-modal and Multi-scale Spatial Environment Understanding for Immersive Visual Text-to-Speech
Rui Liu†, Shuwei He, Yifan Hu, Haizhou Li († Corresponding Author / 通讯作者, Shuwei He is the first student author / 何树伟为导师外学生一作)
- This paper introduces M$^2$SE-VTTS, an innovative multi-modal and multi-scale framework that integrates RGB and depth images with environment captions to effectively model local and global spatial contexts for synthesizing immersive reverberant speech.
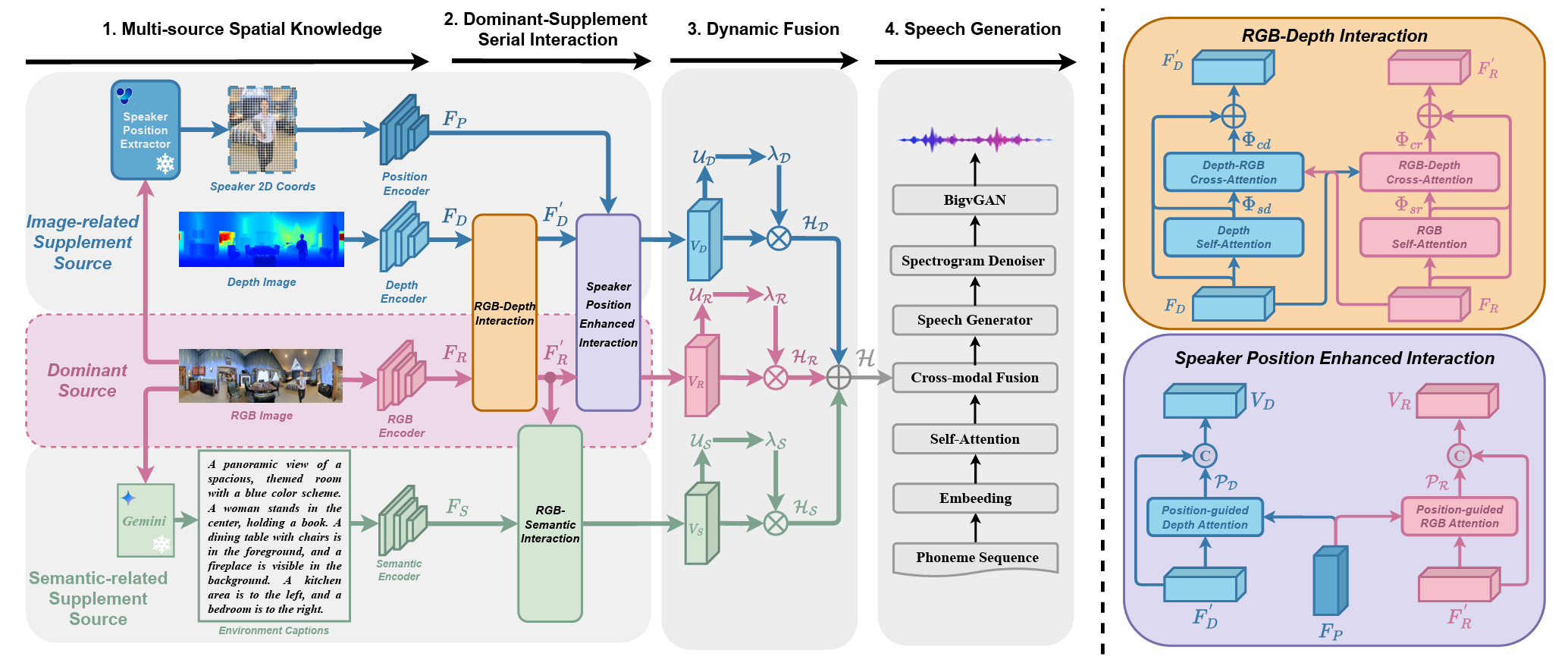
Multi-Source Spatial Knowledge Understanding for Immersive Visual Text-to-Speech
Shuwei He (First Author / 第一作者), Rui Liu
- This paper introduces MS$^2$KU-VTTS, a novel framework that dynamically integrates multi-source spatial knowledge—such as RGB images, depth data, speaker positions, and semantic captions—to generate immersive, environment-matched reverberant speech.
More Publications
- Technical Report ERNIE 5.0 Technical Report, ERNIE Team, Baidu (Shuwei He as Core Contributor / 何树伟为核心参与者)
- Findings of ACL 2026 CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation, Jing Hu, Danxiang Zhu, Xianlong Luo, Dan Zhang, Shuwei He, Yishu Lei, Haitao Zheng, Shikun Feng, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang
- arXiv 2026 CodecCap: High-Fidelity Codec-Inspired Residual Modeling for Dense Video Captioning, Zihan Lin*, Songhe Deng*, Shuwei He*, Danxiang Zhu, Dan Zhang, Yishu Lei, Xianlong Luo, Shikun Feng, Rui Liu (* Equal Contribution / * 共同一作)
🎖 Honors and Awards
- 2025.12 National Scholarship for Graduate Students (研究生国家奖学金)
- 2025.12 Academic Scholarship for Graduate Students (研究生学业奖学金)
- 2023.12 Academic Scholarship for Graduate Students (研究生学业奖学金)
- 2021.12 National Scholarship for Undergraduate Students (本科生国家奖学金)
📖 Educations
- 2023.08 - 2026.06, Master, Inner Mongolia University, Artificial Intelligence
💻 Internships
- 2025.02 - 2026.01, Algorithm Intern, Baidu ERNIE Bot (文心一言), China.